This microservice, produced by iCoSys, is an implementation of BLIP-2 paper. It is a generic and efficient pre-training strategy that easily harvests development of pretrained vision models and large language models (LLMs) for vision-language pretraining. BLIP-2 beats Flamingo on zero-shot VQAv2 (65.0 vs 56.3), establishing new state-of-the-art on zero-shot captioning (on NoCaps 121.6 CIDEr score vs previous best 113.2). Equipped with powerful LLMs (e.g. OPT, FlanT5), BLIP-2 also unlocks the new zero-shot instructed vision-to-language generation capabilities for various interesting applications.
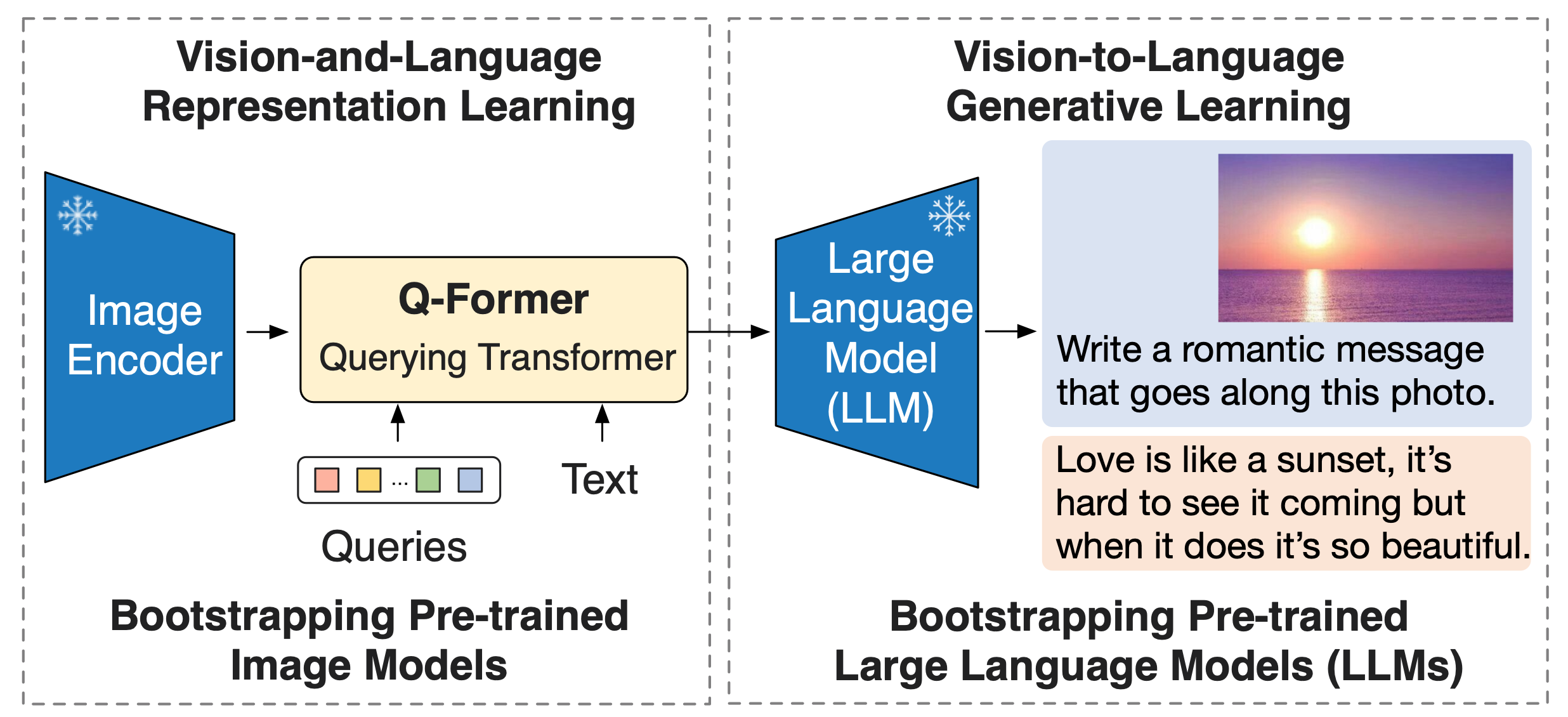
BLIP-2 models are hosted in hunggingface here. Even if the number of trainable parameters is quite high, the inference time is quite low (as long as the image is not too big). The cool thing with huggingface is that BLIP-2 models are wraped with a librairy named bitsandbytes that allows to use the biggest models without using the whole GPU's RAM. For example, a 2.7 Billion parameters model can be used with 9GB of GPU's RAM. Without losing performances, the models become more accessible.
The specification file is defined according to openapi v3 (OAS3).
The OpenAPI specifications are available under the route `/specification` and the Swagger interface to test the API under the route /docs.
Here are several curl and prompt example to test the captioning service:
curl -H "Content-Type: application/json" \
-H "accept: application/json" \
-d '{"images":"array_b64_images","prompt":"this images shows"}' \
-X POST https://icoservices.kube.isc.heia-fr.ch/blip/blip-caption/
curl -H "Content-Type: application/json" \
-H "accept: application/json" \
-d '{"images":"array_b64_images","prompt":"this images shows"}' \
-X POST https://icoservices.kube.isc.heia-fr.ch/blip/blip-caption/
curl -H "Content-Type: application/json" \
-H "accept: application/json" \
-d '{"images":"array_b64_images","prompt":"Question: what is this animal ? Answer: a dog \
Question: what is he doing ? Answer:"}' \
-X POST https://icoservices.kube.isc.heia-fr.ch/blip/blip-caption/
Here are several curl and prompt example to test the text-image matching service:
curl -H "Content-Type: application/json" \
-H "accept: application/json" \
-d '{"images":"array_b64_images","prompt":"a ferrari 488 pista spider"}' \
-X POST https://icoservices.kube.isc.heia-fr.ch/blip/blip-match/
curl -H "Content-Type: application/json" \
-H "accept: application/json" \
-d '{"images":["b64_images"],"prompt":"dog; cat; bear"}' \
-X POST https://icoservices.kube.isc.heia-fr.ch/blip/blip-match/
Feel free to try it out with your own prompts using the web application !
This project and the models are licensed under the terms of the MIT license.
BLIP-2 is working uder LAVIS. This is a Python deep learning library for LAnguage-and-VISion intelligence research and applications. This library aims to provide engineers and researchers with a one-stop solution to rapidly develop models for their specific multimodal scenarios, and benchmark them across standard and customized datasets. Powered by Salesforce, this library is licensed under the terms of the BSD 3-Clause License
For any issue or question, feel free to open an issue on the project or contact us at info@icosys.ch.